728x90
반응형
3. 관계형 데이터
- 데이터 구조 : 릴레이션
=> 데이터의 정적 특성- 연산 : 관계 대수
=> 행위적인 동적 특성- 제약 조건 : 무결성 제약 조건
=> 구조적 제약/행위적 제약
3-1. 관계형 데이터 구조
릴레이션 : 2차원 테이블 형태
관계형 데이터 모델은 테이블을 '릴레이션'이라고 부름
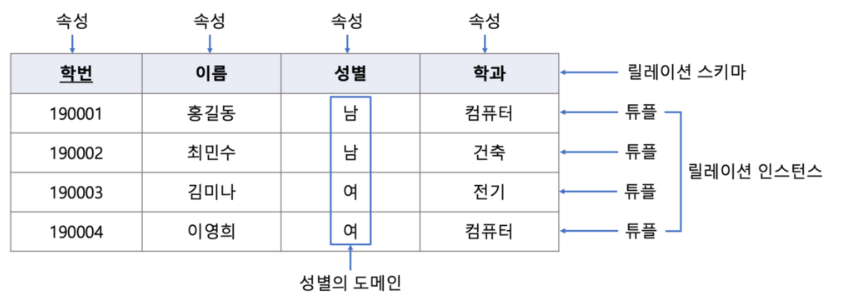
릴레이션 스키마 : 테이블 명 + 속성명 (키 값은 밑줄로 표시)
ex) 학생(학번, 이름, 성별, 학과)
릴레이션 인스턴스 : 튜플들로 구성
ex) {<'S001', '김연아', '여', '컴공'>,<'S002', '홍길동', '남', '경영'>}
데이터 베이스의 구성
- 데이터 스키마 => 데이터 베이스 안의 모든 릴레이션 스키마의 집합 (정적)
- 데이터 인스턴스 => 특정 시점에서의 모든 릴레이션 인스턴스들의 집합 (동적)
3-2. 제약 조건
- 데이터 신뢰성 & 정합성을 유지하기 위해 제약 조건 명세
- 릴레이션의 키(key) : 각 튜플들을 유일한 1개로 식별할 수 있는 속성 (1개 혹은 집합)
- 모든 릴레이션은 키를 가진다.
키의 종류
- 후보키
- 튜플을 유일한 1개로 식별할 수 있는 최소 집합 (기본키의 후보)
- 유일성 + 최소성
- 유일성 : 해당 키를 가지고 튜플을 유일한 존재로 식별 가능
- 최소성 : 키의 집합이 식별을 위한 최소의 조건인지
- 슈퍼키
- 유일성 조건만 만족
- 유일성을 식별하기 위한 최소의 조건이 아닌 다른 조건 있어도 괜찮다
- 기본키
- 후보키 중 한 개 선정
- 선정 기준 : 성능 상의 이점 (속성개수적고, 널값을 갖기 않고, 정적인 속성, 물리적 크기 작음)
- 릴레이션에 접근할 때 사용
- 대체키
- 기본키로 선정되지 못한 후보키
- 외래키
- 특정 릴레이션의 기본키를 참조하는 속성 집합
- 기본키와 외래키는 릴레이션 간 연관성을 표현하며, 연결고리 역할을
- 특별한 경우, 외래키와 기본키가 한 릴레이션 내에 존재할 수 있음
- NULL값을 가질 수 있다.
무결성 제약 조건
- 데이터의 일관성과 정확성에 손상이 없도록 유지되는 특성
- => 공통 제약 사항을 DBMS의 무경설 제약 조건으로 명세하는 방법
- DDL 단계에서 테이블 생성 시, 변경 시 명세 가능하다
- 개체 무결성 제약 조건
- 기본키로 지정된 속성은
NULL값 X+릴레이션 내에서 중복X(유일값)
- 기본키로 지정된 속성은
- 참조 무결성 제약 조건
- 외래키로 지정한 속성은 참조하는 기본키 속성 값과 일치하는 값이나 NULL값만 가질 수 있음
- 자식 릴레이션의 외래키의 속성
- 부모 릴레이션의 기본키의 속성에 존재하는 값 (참조 관계)
- NULL값 (참조 관계가 없는 )
- 도메인 무결성 제약 조건
- 유일성 제약 조건
4. 관계대수
관계대수?
: 어떤 방법으로 두 릴레이션의 관계를 정해서 새로운 릴레이션을 생성할지에 대한 연산들의 집합
=> 관계형 데이터 모델과 SQL 데이터 베이스 언어의 이론적 토대를 제공
4-1. 관계대수 연산
관계대수는 2그룹으로 분류된다.
- 집합 연산 : 수학 집한 이론 기반
- 관계 연산 : 관계형 데이터 모델을 위해 추가된 연산
집합 연산
- 릴레이션을 튜플 집합 또는 속성 집합으로 간주

- 합집합
- 두 릴레이션의 모든 튜플 반환 (중복은 제거)
- 교집합
- 두 릴레이션의 공통 튜플 반환
- 차집합
- R1 릴레이션에는 있고, R2 릴레이션에는 없는 튜플 반환
- 카티션 프로덕트
- 튜플을 수평으로 결합
- R1 * R2 => 모든 튜플을 반복하여 앞뒤로 연결
관계 연산

- 셀렉트
- 릴레이션에서 특정 투플을 추출하는 연산
- 릴레이션 수평 분할
- 프로젝트
- 릴레이션에서 특정 속성을 추출하는 연산
- 릴레이션 수직 분할
- 조인
- 두 릴레이션의 공통 속성을 기준으로 조인 조건을 만족하는 투플을 수평으로 결합
- 카티션 프로덕트 한 후에 -> 결과 릴레이션에서 조건에 만족하는 튜플을 셀렉트하는 결과와 동일
- 세타조인 : 비교연산자 중 하나 사용
- 동등조인 : 비교연산자 중 '=' 사용
- 자연조인 : 동등 조인 한 후에 중복 속성을 자동으로 제거한 조인
- 세타조인 > 동등조인 > 자연조인
- 디비전
- 특정 값들을 모두 가지고 있는 튜플을 찾는 연산
- R1 % R2 => R1이 R2의 모든 속성을 포함
확장 연산
- 세미 조인 연산
- 두 릴레이션의 자연조인 결과에서 한쪽 릴레이션(왼쪽/오른쪽) 속성만 반환
- 외부 조인 연산 (Outer Join)
- 자연 조인 결과에 포함되지않는, 조인에 실패한 튜플까지 모두 포함하도록 확장한 연산 -> 조인할 대응 튜플이 없는 경우 NULL 값으로 채워 반환
- OUTER JOIN : 두 릴레이션 항목 모두 합침
- INNER JOIN : NULL이 존재하는 튜플은 제외
- 외부 합집합 연산 (Outer Union)
- 합집합은 원래 속성이 일치해야 합집합을 수행하지만, 부분적으로만 속성이 일치해도 OUTER UNION은 가능하다. 일치하지 않는 속성의 부분은 NULL 값으로 채워 반환한다.
4-2. 관계 대수의 활용
SQL 문장을 내부적으로 처리하기 위해 DBMS는 그 처리순서와 방법을 결정
하나의 SQL 쿼리문은 여러 관계대수로 표현될 수 있다.
DBMS는 SQL 쿼리문을
- 어떤 관계대수를 먼저 수행하고
- 어떤 관계로 식을 설정할지
를 결정 => DBMS의 query 처리기는 여러 가능한 부모 쿼리트리들을 최적에 가까운 트리로 변환해 가며 하나의 query 실행 계획을 결정한다.
쿼리 최적화(query optimization) : 연산 순서를 조정함으로써 연산으로 생기는 중간 릴레이션의 크기를 최소화
- => 보통 select 연산이나 project 연산을 먼저 실행시키면 중간 릴레이션의 투플 수나 속성 수를 줄일 수 있다!
주로 활용하는 방법
- index 생성
- 하지만 index 생성으로도 성능이 좋아지지 않을 수 있음
- 그럴때는 Full Scan이 유리할 때도 있음
- 확인하기 위해 실행 계획 (query execution plan) 확인 가능
- 추가적 방법으로 테이블의 분포 등을 확인하는 통계데이터를 확인할 수도 있음
728x90
반응형
'DB > 이론 및 개념' 카테고리의 다른 글
| # 05. 데이터 베이스 모델링 (0) | 2024.04.25 |
|---|---|
| #03. 뷰와 인덱스 (정의, 사용법) (0) | 2024.04.25 |
| #01. 데이터베이스 개념 및 데이터베이스 시스템 (+DBMS) (0) | 2023.08.09 |
| [DB] ERD / 다대다 관계 (many-to-many relation) - 교차 엔티티 Association Entity (0) | 2020.10.12 |
| [DB] DataBase Normalization 데이터베이스 정규화, 복합기본키 (2) | 2020.09.23 |

