SQL
EMPLOYEE TABLE
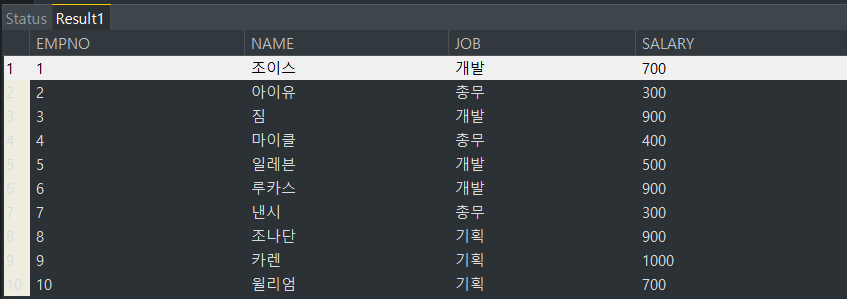
1. JOB 컬럼을 기준으로 그룹화하여, JOB, 사원수, 평균월급(반올림) 내림차순으로 조회해보기
* 반올림 함수 : ROUND ( [column name] , [몇번째 자리수까지 표시할것인지] )
SELECT job, COUNT(*) AS 사원수, ROUND(AVG(salary), 2) AS 평균월급
FROM employee
GROUP BY job
ORDER BY 평균월급 DESC;

2. 1번 문제에 JOB 별 평균 월급이 500을 초과하는 JOB들 조회하는 것으로 그룹 조회 조건을 추가
(HAVING절)
SELECT job, COUNT(*) AS 사원수, ROUND(AVG(salary), 2) AS 평균월급
FROM employee
GROUP BY job
HAVING AVG(salary) > 500
ORDER BY 평균월급 DESC;

3. job 그룹 별로 salary의 최고값 조회 --> JDBC로 구현해볼 예제
-- 조회 대상 : job, highSalary
-- 정렬 조건 : highSalary 내림차순
SELECT job, MAX(salary) AS HIGHSAL
FROM employee
GROUP BY job
ORDER BY HIGHSAL DESC;
Java JDBC
TestDAO class (main class)
1. job 그룹 별로 salary의 최고값 조회 : getJobGroupInfoGroupByJob method
- 조회 대상 : job, highSalary
- 정렬 조건 : highSalary 내림차순
/TestGroupBy.java
package test;
import java.util.ArrayList;
import java.util.HashMap;
import model.EmployeeDAO;
public class TestGroupBy {
public static void main(String[] args) {
try {
EmployeeDAO dao = new EmployeeDAO();
// 조건 : job 그룹 별로 salary의 최고값 조회
// 조회 대상 : job, highSalary
// 정렬 조건 : highSalary 내림차순
ArrayList<HashMap<String, Object>> list =
dao.getJobGroupInfoGroupByJob();
for (int i = 0; i < list.size() ; i++) {
System.out.println(list.get(i).get("job") + " "
+ list.get(i).get("highsal"));
}
/* 출력값 :
* 기획 1000
* 개발 900
* 총무 400
*/
} catch (Exception e) {
e.printStackTrace();//예외 원인과 발생 경로를 출력
}
}
}
2. JOB의 종류만 출력 : getJobKind method
- 조회 대상 : job의 종류
/TestDistinct.java
package test;
import java.util.ArrayList;
import model.EmployeeDAO;
public class TestDistinct {
public static void main(String[] args) {
try {
EmployeeDAO dao = new EmployeeDAO();
ArrayList<String> list = dao.getJobKind();
for (int i = 0; i < list.size(); i++) {
System.out.println(i+1 +". "+list.get(i));
/* 출력값:
* 1. 총무
* 2. 개발
* 3. 기획
*/
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
DAO ( Data Access Object ) class
/EmployeeDAO.java
주요 method
1. getEmpByLowSal : input - String job / output - ArrayList<EmployeeVO>
: 서브쿼리 연습
2. getJobGroupInfoGroupByJob : input - X / output - ArrayList<HashMap<String, Object>>
: groupby 쿼리 연습
: while문 안에서 각 row가 올 때 마다, *결과의 한 행에 대한 정보를 VO로 받는 대신 HashMap으로 받아준다*
1) map 형성 (key - String, value - Object)
- 테이블의 column명을 key로, column 내용(요소)를 value로
2) 테이블의 row(한 줄) 당 형성된 map을 list에 추가
3. getJobKind : input - X / output = ArrayList<String>
: distinct 연습
package model;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.HashMap;
import common.DbInfo;
public class EmployeeDAO {
// Constructor - Driver Loading
public EmployeeDAO() throws ClassNotFoundException {
Class.forName(DbInfo.DRIVER_NAME);
}
// closeAll 1
public void closeAll(PreparedStatement pstmt, Connection con) throws SQLException {
if (pstmt != null)
pstmt.close();
if (con != null)
con.close();
}//closeAll
// closeAll 2
public void closeAll(ResultSet rs, PreparedStatement pstmt, Connection con) throws SQLException {
if (rs != null)
rs.close();
closeAll(pstmt, con);
}//closeAll
//getEmpByLowSal method (SubQuery 연습)
public ArrayList<EmployeeVO> getEmpByLowSal(String job) throws SQLException{
Connection con = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
ArrayList<EmployeeVO> list = new ArrayList<EmployeeVO>();
try {
con = DriverManager.getConnection(DbInfo.URL, DbInfo.USER, DbInfo.PASS);
StringBuilder sql = new StringBuilder();
sql.append("SELECT EMPNO, NAME, JOB, SALARY ");
sql.append("FROM EMPLOYEE ");
sql.append("WHERE SALARY = ");
sql.append("( SELECT MIN(SALARY) ");
sql.append("FROM EMPLOYEE ");
sql.append("WHERE JOB = ? )");
pstmt = con.prepareStatement(sql.toString());
pstmt.setString(1, job);
rs = pstmt.executeQuery();
while(rs.next()) {
EmployeeVO vo = new EmployeeVO(rs.getString(1),
rs.getString(2), rs.getString(3),
rs.getInt(4));
list.add(vo);
}
} finally {
closeAll(rs, pstmt, con);
}
return list;
}
//getJobGroupInfoGroupByJob method
public ArrayList<HashMap<String, Object>> getJobGroupInfoGroupByJob() throws SQLException {
Connection con = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
ArrayList<HashMap<String, Object>> list =
new ArrayList<HashMap<String, Object>>();
try {
con = DriverManager.getConnection(DbInfo.URL, DbInfo.USER, DbInfo.PASS);
StringBuilder sql = new StringBuilder();
sql.append("SELECT job, MAX(salary) AS HIGHSAL ");
sql.append("FROM employee ");
sql.append("GROUP BY job ");;
sql.append("ORDER BY HIGHSAL DESC ");
pstmt = con.prepareStatement(sql.toString());
rs = pstmt.executeQuery();
while(rs.next()) {
//결과의 한 행(row)에 대한 정보를 VO대신 Map으로 담는다
HashMap<String, Object> map = new HashMap<String, Object>();
map.put("job", rs.getString(1));
map.put("highsal", rs.getInt(2));
list.add(map);
}
} finally {
closeAll(rs, pstmt, con);
}
return list;
}
//getJobKind method
public ArrayList<String> getJobKind() throws SQLException {
Connection con = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
ArrayList<String> list = new ArrayList<String>();
try {
con = DriverManager.getConnection(DbInfo.URL, DbInfo.USER, DbInfo.PASS);
String sql = "SELECT DISTINCT(JOB) " +
"FROM employee";
pstmt = con.prepareStatement(sql);
rs = pstmt.executeQuery();
while(rs.next()) {
list.add(rs.getString(1));
}
} finally {
closeAll(rs, pstmt, con);
}
return list;
}
}



